|
I am a Principal Researcher at Microsoft Cloud+AI where I work on the research and development of Computer Vision and Machine Learning related products. I am currently pursuing Multimodal research and development as part of the Responsible AI pillar under Azure Cognitive Services, supporting products like Azure AI Content Safety and Azure OpenAI. Previously, I have worked on AutoML as part of the Microsoft Custom Vision Service. I did my Master's in Computer Vision at Robotics Institute, Carnegie Mellon University where I worked with Prof. Kris Kitani on model compression and Hypernetworks. I have also worked at Amazon as a Software Development Engineer. I graduated with a B.Tech. in Computer Science and Engineering from Indian Insitute of Technology Ropar with the President of India Gold Medal. I have won the Microsoft Imagine Cup India and Indian National Academy of Engineering Innovate Student Project Award in 2016 for my project SpotGarbage. Email / Google Scholar / Twitter / Github / LinkedIn |

|
|
|
I'm interested in computer vision, multmodal machine learning, automated machine learning (AutoML), semi-/self-supervised learning and meta learning. |

|
Junwen Chen*, Gaurav Mittal*, Ye Yu, Yu Kong, Mei Chen CVPR, 2022 paper GateHUB introduces a novel gated cross-attention along with future-augmented history and background suppression objective to outperform all existing methods on online action detection task on all public benchmarks. |
|
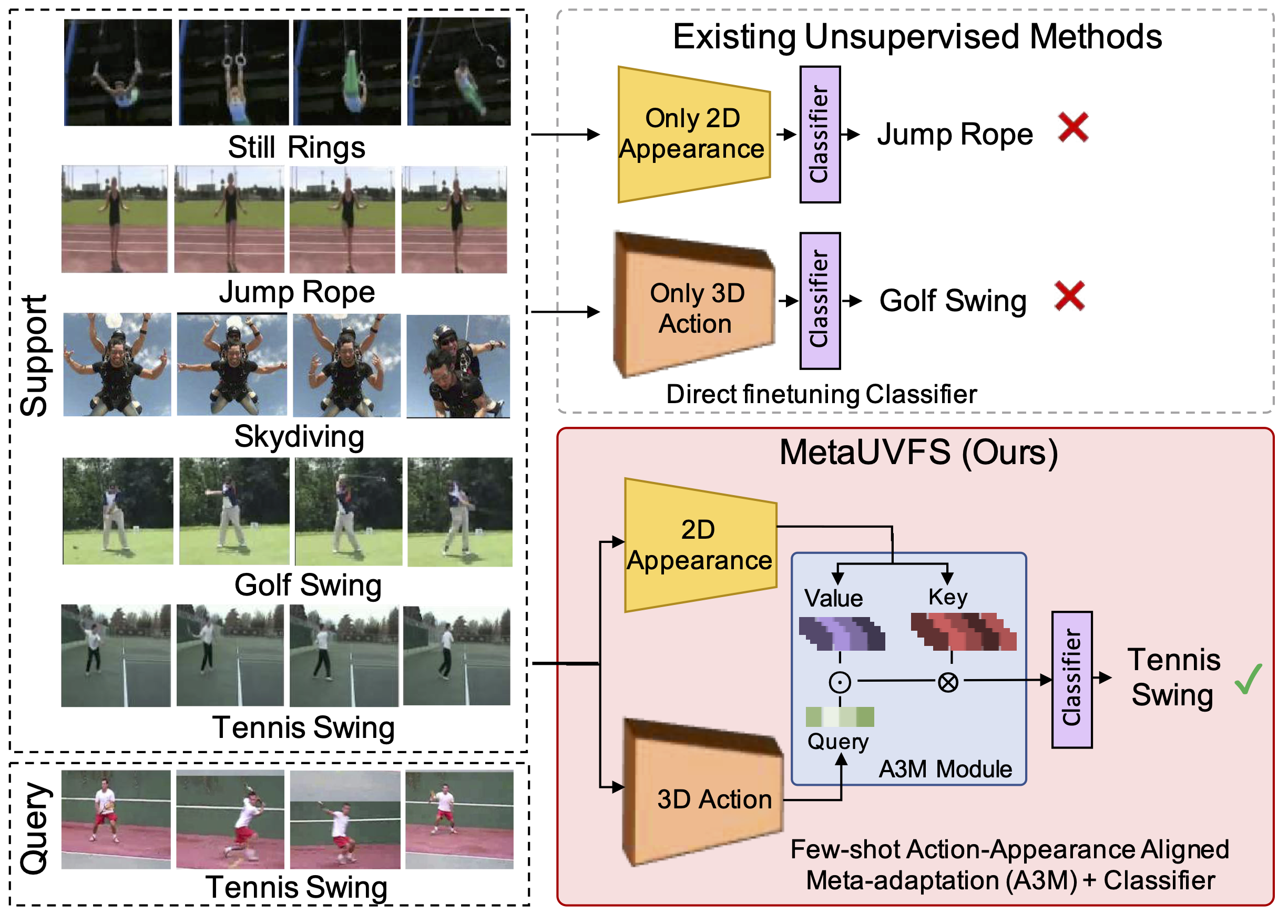
Jay Patravali*, Gaurav Mittal*, Ye Yu, Fuxin Li, Mei Chen ICCV, 2021 (Oral Presentation, 3% acceptance rate) paper First Unsupervised Meta-learning algorithm for Video Few-Shot action recognition. It comprises a novel Action-Appearance Aligned Meta-adaptation (A3M) module that learns to focus on the action-oriented video features in relation to the appearance features via explicit few-shot episodic meta-learning over unsupervised hard-mined episodes. |
|
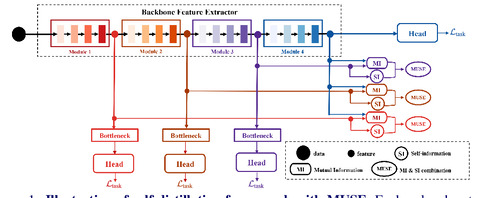
Yu Gong*, Ye Yu*, Gaurav Mittal, Greg Mori, Mei Chen BMVC, 2021 paper A novel information-theoretic approach to introduce dependency among features of a deep convolutional neural network (CNN). It jointly improve the expressivity of all features extracted from different layers in a CNN using Additive Information and Multiplicative Information. |
|
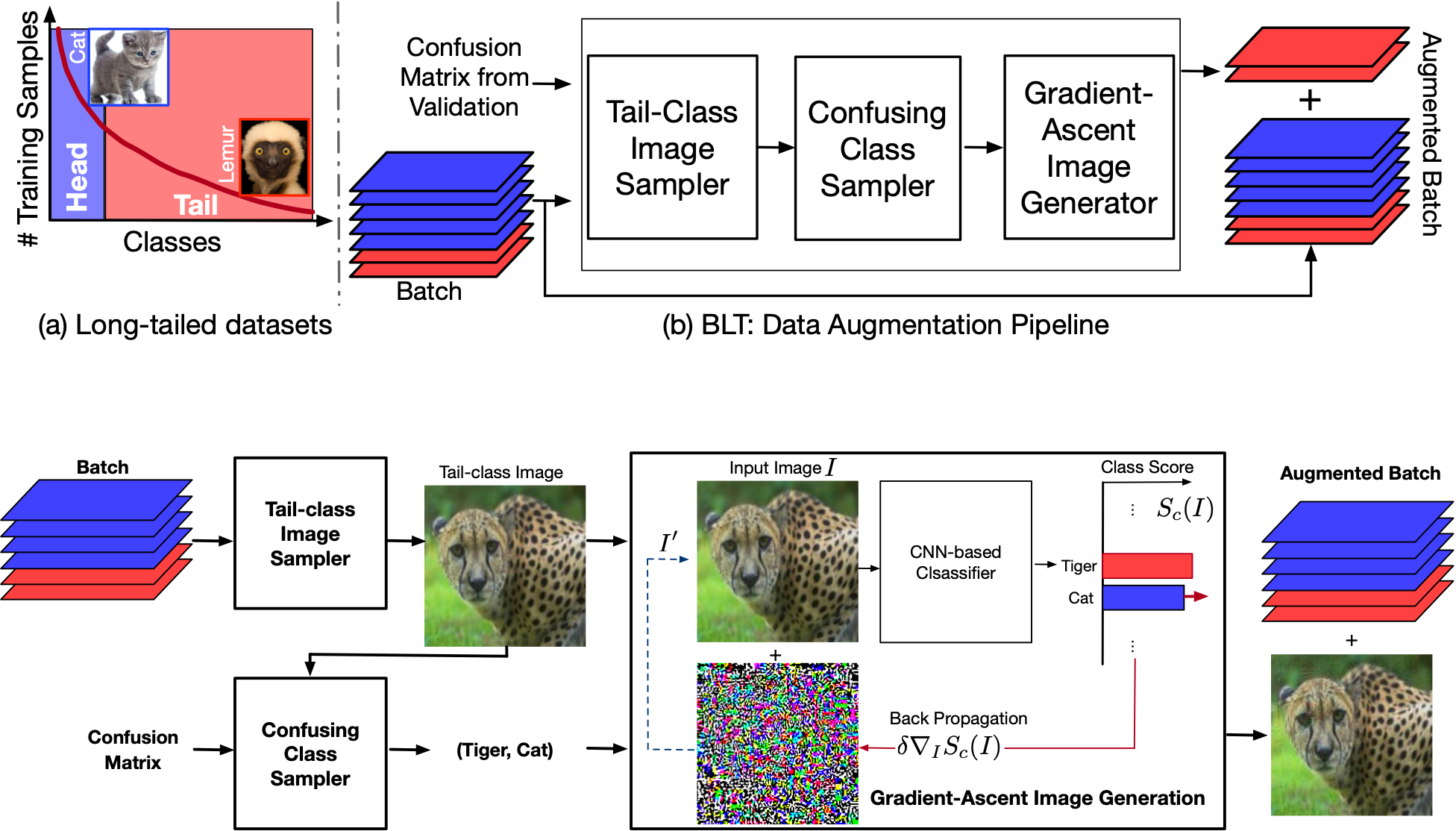
Jedrzej Kozerawski, Victor Fragoso, Nikolaos Karianakis, Gaurav Mittal, Matthew Turk, Mei Chen ACCV, 2020 paper / code / video A novel data augmentation technique that uses gradient-ascent to generate extra training samples for tail classes in a long-tail class distribution to improve generalization performance of a image classifier for real-world datasets exhibiting long tail. BLT avoids dedicated generative networks for image generation, thereby significantly reducing training time and compute. |
|
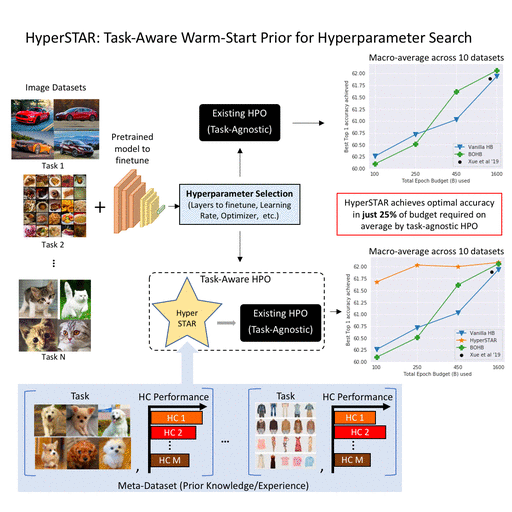
Gaurav Mittal*, Chang Liu*, Nikolaos Karianakis, Victor Fragoso, Mei Chen, Yun Fu (* Equal Contribution) CVPR, 2020 (Oral Presentation, 5.7% acceptance rate) paper / video A task-aware method to warm-start Hyperparameter Optimization (HPO) methods by predicting the performance for a hyperparamter configuration via a learned task (dataset) representation. |
|
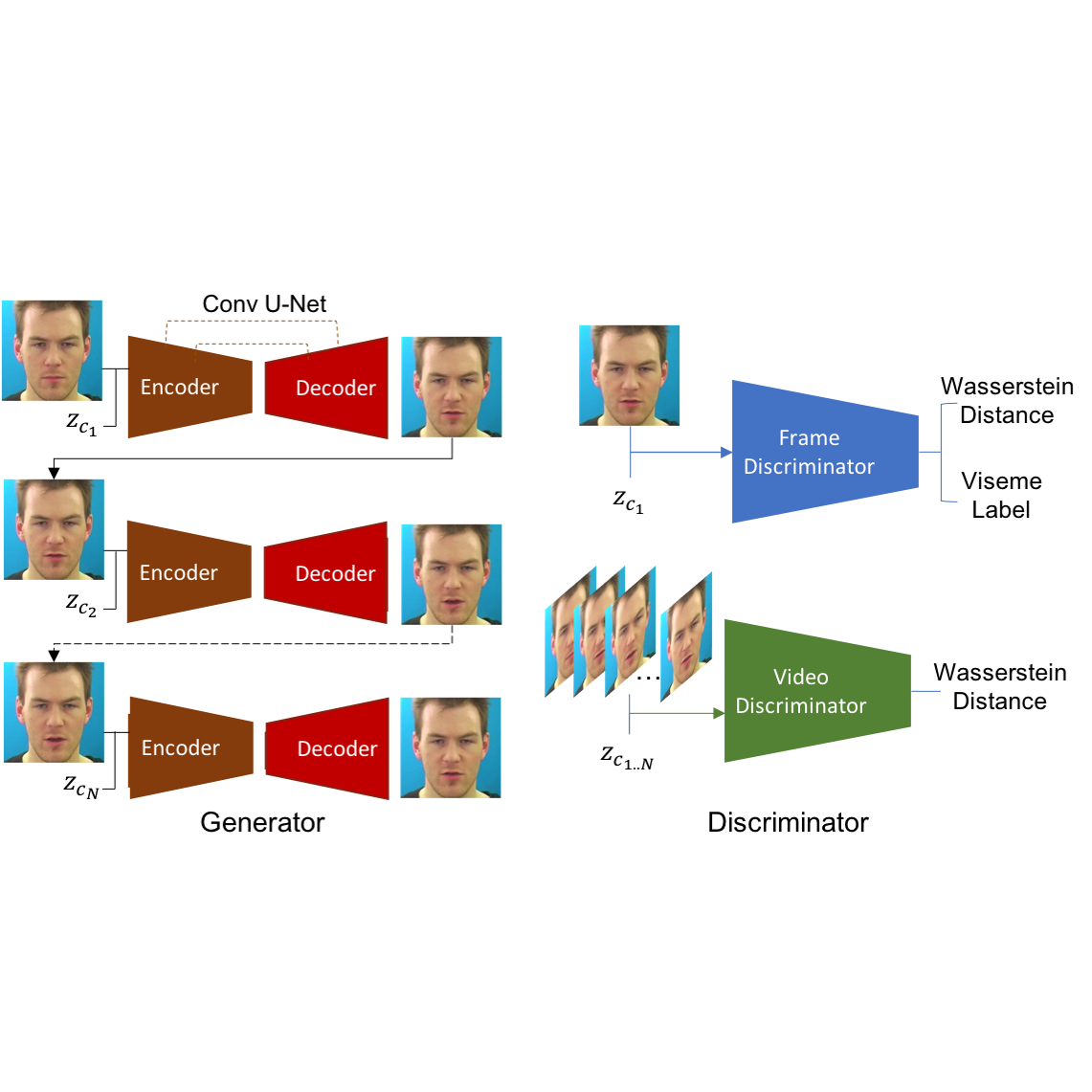
Gaurav Mittal, Baoyuan Wang WACV, 2020 paper / video / arXiv To make talking head generation robust to such emotional and noise variations, we propose an explicit audio representation learning framework that disentangles audio sequences into various factors such as phonetic content, emotional tone, background noise and others. When conditioned on disentangled content representation, the generated mouth movement by our model is significantly more accurate than previous approaches (without disentangled learning) in the presence of noise and emotional variations. |

|
Gaurav Mittal*, Shubham Agrawal*, Anuva Agarwal*, Sushant Mehta*, Tanya Marwah* (*Equal Contribution) ICLR, 2019 DeepGenStruct Workshop paper / arXiv Proposed a method to generate an image incrementally based on a sequence of scene graphs such that the image content generated in previous steps is preserved and the cumulative image is modified as per the newly provided scene information. |

|
Tanya Marwah*, Gaurav Mittal*, Vineeth N Balasubramanian (* Equal Contribution) ICCV, 2017 paper / code / arXiv Proposed a network architecture that learns long-term and short-term context of the video data and uses attention to align the information with accompanying text to perform variable length semantic video generation on unseen caption combinations. |
|
Gaurav Mittal*, Tanya Marwah*, Vineeth N Balasubramanian (* Equal Contribution) ACM Multimedia, 2017 (Oral Presentation, 7.5% acceptance rate) paper / arXiv Combines a variational autoencoder (VAE) with recurrent attention mechanism to create a temporally dependent sequence of frames that are gradually formed over time. |

|
Gaurav Mittal, Kaushal B Yagnik, Mohit Garg, Narayanan C Krishnan ACM UbiComp, 2016 video / code / paper/ dataset Designed a fully convolutional network to detect and coarsely segment garbage regions in the image. Built an smartphone app, SpotGarbage, deploying the CNN to make on-the-device detections. Also introduced a new Garbage-In-Images (GINI) dataset. |
|
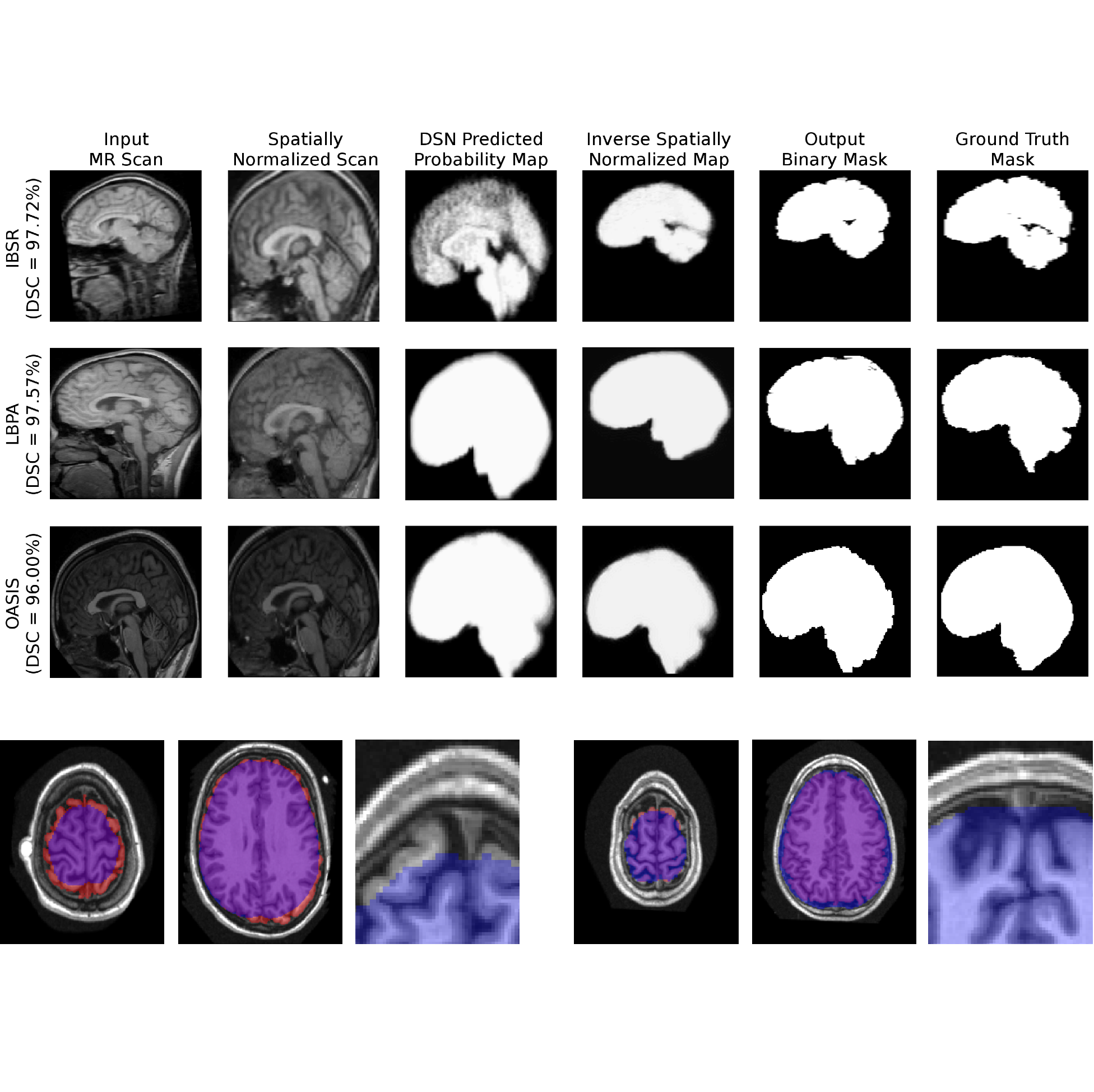
Apoorva Sikka*, Gaurav Mittal*, Deepthi R Bathula, Narayanan C Krishnan (*Equal Contribution) ICVGIP, 2016 paper Proposed a novel encode-decoder network for brain extraction from T1-weighted MR images. The model operates on full 3D volumes, simplifying pre- and post-processing operations, to efficiently provide a voxel-wise binary mask delineating the brain region. |
|
|
|

|
Workshop on Neural Architecture Search for Computer Vision in the Wild (NASFW) WACV 2020 |
|
Respectfully copied from Jon Barron's website. |